Proxy Setup for Web Scraping: Never Get IP Banned Again (Complete Guide)
🧩 Table of Contents
Why websites block IPs
You write a very simple scraper. You try one request. It works. Then it does it when you scale it up to 500 requests, and all of a sudden you are not even there anymore, or even worse, you get a wall of 403s, 429s, redirects, and CAPTCHAs. If this sounds familiar, then you’re not doing anything wrong. You are facing the harsh truth of today’s anti-bot technologies.
There are not many sites out there that block your IP for the sake of it. They do this because your traffic begins to differ from their typical browsing patterns. If you’re aware of the websites that look for things, the bans make much sense.
Current Sites that are commonly detected
-
Too many requests from a single IP address: This is the large one. If one address is sending hundreds or thousands of requests in a short period of time, rate limiters will be activated. It is sometimes possible to see a clear 429: Too Many Requests. At other times, the website simply lags or silently delivers broken pages.
-
Low trust IP ranges: There are many systems which use IP ranges that are assigned a risk score. Major cloud service providers have their datacenter IPs looked at more suspiciously than residential and mobile IPs. Why? Because there is a lot of automation traffic that begins there.
-
Machine like timing: Requests within 2 seconds? This is not how people in the real world search. Humans are messy. We take breaks, click around, load more assets, open multiple tabs and abandon pages during the process. There should be more “mess” in bots.
-
Fingerprint inconsistencies: If the IP location is Germany but your browser indicates an unusual device location and timezone and/or headers, this is an indicator. By itself, this may not be a big deal. It’s a lot more important when added to the high volume of requests.
-
Session level tracking: Many people think that they can change their IP addresses and that will do. Not always. Cookies, local storage, browser signatures, and behaviour history can link up requests. Yes, there are proxies, but they are best used along with consistent session logic.
In a nutshell, websites are blocking IPs if your traffic appears to be automated, abusive or statistically bizarre. A proxy’s role is to spread out, normalize and provide context to that traffic, so you don’t seem like one big computer.
What a proxy does in web scraping
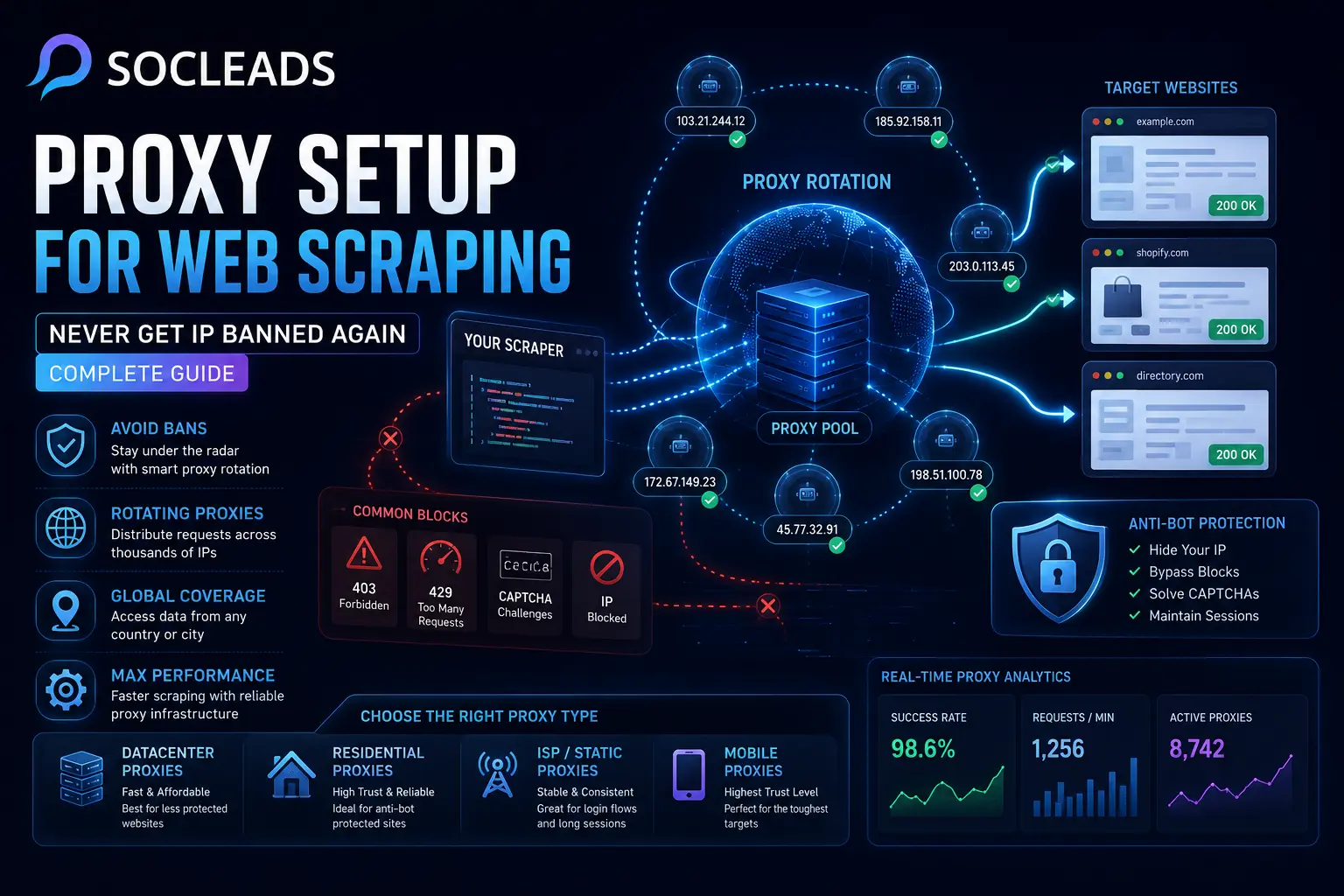
A web scraping proxy is an intermediary between the website that you want to access and the web scraper. Your request is not direct, but goes through the circuitous route of: Your scraper → proxy → target site → proxy → your scraper
The traffic is generated from the proxy IP, not your local IP or your server’s IP, from the point of view of the target site. This addresses a few practical issues.
The necessity and value of Proxies in Scraping
-
IP masking: The site won’t be able to see your real IP. That provides you with a separation layer between your infrastructure and destination.
-
IP rotation: You can rotate multiple IPs instead of sending all the requests from one IP. This ensures load dispersal and reduces the risk of single IP bans.
-
Location targeting: Looking for search results in the US, prices in the UK and local listings in Germany? A well-designed proxy provider allows you to select geographic location.
-
Session control: If the scraping workflow needs to be stable, such as a shopping cart or multi-step navigation, proxies can have the same IP address for a certain amount of time. These are most commonly referred to as sticky sessions.
Common proxy protocols
-
HTTP and HTTPS: These are the most primary ones for web scraping. They are easy to set up, and are compatible with both HTTP clients and scrapers and browsers.
-
SOCKS5 proxies: These are located at a lower level of the network and can handle a greater diversity of traffic. These are particularly helpful in browser automation or tools that perform more than just fetching a page.
Every time people are looking for best proxies for web scraping, rotating proxies, or proxy setup for web scraping, they are asking themselves this one question: “How do I make myself look less like one noisy bot and more like distributed, normal traffic?”
Types of proxies and when to use them
Not every proxy is created equal. Many scraping projects will fail here. Each person purchases the lowest-priced pool they are able to purchase, aims it at a high protected target and is bewildered at the lack of anything lasting longer than a day. I have witnessed that error so many times, I would say it was predictable.
Datacenter proxies
These are provided by cloud service providers or hosts.
-
Their strengths are: High performance, high throughput, cost-effective scaling, and easy provisioning.
-
Where they struggle: They can be quickly identified by many targets. Trust is lower from the off.
-
Best use cases: Simple websites, internal monitoring, pages with low anti-bot protection, high volume collection with some failures allowed.
Residential proxies
These are IP addresses that are given to consumers by their internet service provider.
-
What they are good at: More trust = better page ranking on anti bot heavy sites = more natural metadata = useful for localized pages.
-
Where they struggle: More expensive and potentially less responsive.
-
Best use cases: Where speed is not really an issue and bans are, ecommerce scraping, travel data, social platforms, local SEO data collection, and all other projects.
ISP proxies
These are also known as static residential proxies, which attempt to merge the qualities of datacenter and residential proxies.
-
Strengths: High trust profile and long term sessions.
-
Where they struggle: Limited number of pools and prices.
-
Best use cases: Logins, account based browsing, cart persistence, and repeat access from what seems to be the same user.
Mobile proxies
These are from the cellular networks.
-
What they are good at: Mobile traffic naturally shares many users, mobile devices, and very high trust and tolerance on targets that are difficult.
-
Where they struggle: Expensive, inconsistent and slower speeds.
-
Best use cases: Only the hardest targets that are still burning with other proxy types.
Shared vs dedicated proxies
Shared proxies are utilized by a number of customers. Though they are less expensive, someone else could break your IP reputation before you ever reach it. Dedicated proxies are reserved for you! These are more expensive, but provide a purer sense of control during operation and consistency.
Public proxies are technically an option. Realistically? Not for any serious reasons. They don’t last, they’re typically a time sink, and they are often abused.
Comparison table: proxy options
| Proxy type | Best for | Pros | Cons |
|---|---|---|---|
| Datacenter | Low to medium protection sites | • Fast execution • Low cost • Easy to scale |
• Easier to detect • Lower trust on many targets |
| Residential | Harder targets, location sensitive pages | • Higher trust • Better survival rates • Good geo accuracy |
• More expensive • Slower than datacenter |
| ISP / static residential | Sticky sessions, login flows | • Stable long sessions • Good trust profile |
• Pricey • Smaller supply |
| Mobile | Very heavily protected targets | • Very strong trust • Harder to ban cleanly |
• Very expensive • Less predictable speed |
| Managed scraping API | Teams that want results without managing infrastructure | • Rotation built in • Easier scaling • Less dev overhead |
• Less raw control than fully DIY |
How to reduce bans with smart scraping tactics
A good proxy setup should have only one layer. Proxies don’t hide you. They help to make traffic more manageable. The rest depends on how you utilize them.
Distribute the load on IPs
If an IP is on 5000 requests then it looks suspicious. The traffic profile is quite different if the 1,000 IPs make 5 requests, but with more of a natural distribution. Thus, the proxy rotation for Web scraping functions. You aren’t hiding. You’re spreading behaviour in a manner more representative of real user traffic.
Select from the available rotation options, depending on the use case
-
Per request rotation: Best for public pages where each request is unique. Consider product listing, SERP pages, news archives, directories.
-
Per session rotation: Ideal for tasks related to cookies, logins, shopping carts, or multiple-page flows. Abusing too hard in this area can lead to mismatches in sessions.
Manage geography, manage diversity of ASN
A site can not only take into account the nation where the IP is originating from. It could also pay attention to your network resource. When all of the requests originate from a single cloud ASN or single region that can become detectable. Ideally, there is a broad mix of countries, regions and providers when that is appropriate for the use scenario.
Use error aware rotation
Do not just keep sending a proxy to the queue, if it is returning repeated 403 or 429 responses. Mark it as degraded, cool it down and switch routes. A good system will monitor:
-
Success rate by proxy
-
403/429 counts by proxy
-
The median latency provided as a proxy.
-
Determine the frequency of captcha by target or proxy.
These signals eliminate guesswork and replace it with data.
Even for rate limited items it can apply
This is something that’s frequently overlooked. Individuals purchase high end residential proxies and then use them at a ridiculous speed. It’s like putting on the perfect disguise and then running into the room and yelling. Low and varying rates of request typically get older than aggressive and constant throughput. When data is scraped from the public, it is typically better to be slow for stability.
How to set up proxies for scraping
Let’s look at the nuts and bolts. What does it mean to have a usable proxy setup for web scraping?
Step 1: Select the right sourcing model
There are 3 primary methods to do it.
-
Raw proxy provider: Access to IPs or endpoints and the management of the rest managed by yourself.
-
Managed proxy network or scraping API: You rely on one provider endpoint, and leave the majority of the rotation logic to the service.
-
Full scraping platform: You don’t have to worry about rotating proxies, retries, extracting and sometimes rendering as well.
This is the area in which SocLeads really shines. Rather than forcing you to integrate proxies, browsers, selectors, retries and parsing logic from various vendors, it brings the process together into a cleaner workflow. That’s a significant advantage for teams that are goal-oriented.
Step 2: Install or accept an installation of a proxy pool
If you’re self managing, your pool should be monitoring more than just an IP and port. At least you’d like metadata such as: Proxy type, Country or city, Auth method, Sticky session capability, Health score, Recent status codes. Without metadata, each time you retry it’s just guesswork.
Step 3: Connect the proxies to your HTTP client
The vast majority of the HTTP libraries can support setting proxy configuration directly. A proxy endpoint is defined and requests are sent via the endpoint. In many cases the environment variables can also be used to have the traffic go through the proxy without explicitly hardcoding it in all the request handlers.
The typical setup requires:
-
Proxy host and port
-
User names and passwords (when needed)
-
The protocol to use, like HTTP, HTTPS, or SOCKS5.
-
Timeout values
-
Retry logic rules
Thereafter, you select which assignment is: The static will be applied to the session, Rotated every request, Rotated each N requests, or Only changed if there is an error.
Step 4: Test with a low volume first
Avoid going in to the production scale before conducting controlled tests. Many of the bans happen because of bugs, such as an infinite retry, cookie logic or missing headers.
Do little and check:
-
What is the success rate of requests per IP?
-
Are redirects increasing?
-
Does the content return or are block pages returned?
-
Is response time changing rapidly over time?
This is one understated advantage to teams that choose to use a managed stack to start their project. A service such as SocLeads takes care of a lot of the IP selection, session routing and request hygiene. You’re able to dedicate more time to actually testing the quality of the extraction and less time debugging infrastructure.
Step 5: Add logging from day one
You want to put out a trace for every request that will log: Target URL, Timestamp, An identifier for a proxy server or session for a proxy server, Status code, Latency, Retry count, The results are: content signature or page type result.
This makes diagnosis of ban easier. If you don’t have logs, each scraping problem appears to be random. Logs come up by the wayside.
Headers, user agents, and realistic traffic patterns
Proxies are the routing layer and headers and timing are the body language. They inform the site of what type of client you seem to be.
User agent selection
One of the easiest ways to be flagged is by having a default library user agent. An identifier or a simple label like a plain Python requests identifier makes your automation too easy to spot. It’s better to have convincing user agents that are associated with popular browsers and devices. Variety is not the important thing, it is cohesiveness. If you say you’re a modern mobile browser, the rest of your headers should say it too.
Supporting headers
Consider using the following headers:
-
Accept
-
Accept Language
-
Accept Encoding
-
Connection
-
If fitting, reference the one who referred them to you.
It should not be crap. Realism beats chaos. Few, consistent header formats tend to be better than random combinations per request.
Delay and jitter
Rotation of IPs is important even. When a lot of requests are requested at equidistant times it looks like it was driven by a machine. A small variation in wait time results in less uniform traffic and provides space for the target infrastructure.
A practical pattern usually is something like:
-
Random waits between consecutive requests (short)
-
More page breaks between page groups or between pagination batches.
-
Backoff after retries / possible rate limits
It’s not sexy, but it is effective.
Ensure that state is preserved when the site requires it
Let the session store the cookies if applicable when using cookies at the site. It’s also weird to see every page hit from a new anonymous name, as opposed to certain abuse of the same name. Many times this is seen in multi-step flows. Browse listing, open detail page, view related page, perhaps add a filter, proceed. Such a sequence typically occurs in the same session context.
Heads on the wall and harder to get at
Sometimes, just HTTP requests are sufficient. Sometimes they just aren’t near. There are a lot of websites these days that rely on the JavaScript rendering, browser challenges, dynamic tokens, and more advanced checks which require a bit more real browser functionality.
Use a browser layer when necessary
Browser automation is likely to be required if:
-
The content on the page will not be displayed until JS runs!
-
For important APIs, it is necessary to create tokens on the client side.
-
The challenge to the target is more advanced bot challenge.
-
Your scraper continues to get the partial markup.
Using tools such as Playwright, Puppeteer or Selenium will help, but scaling up can present new challenges. The costs of resources increase, browser fingerprinting becomes a problem, and proxy routing becomes more complex.
Again, there are platforms that combine rendering and proxy with a twist. In particular, SocLeads eliminates much of the hidden plumbing. You don’t just get a collection of IPs. You’re receiving orchestration from browsers, sessions, routing and extraction. This is why it is superior to most solutions which are based on a single proxy only in real workflows.
Monitoring, maintenance, and keeping IPs healthy
A proxy network is not set once and forgotten. Even the best IPs degrade over time. Sites update defenses. Networks shift. Previously clean routes get challenged more often. The setups that stay reliable are the ones with active feedback loops.
Metrics to track
The essentials are:
Request success rate
403 rate
429 rate
Timeout rate
Median response time
Block page frequency
Captcha incidence
You can break this down per proxy, per region, per target domain, and per session type.
Know when a proxy is burning out
Here are the typical warning signs:
Success rate starts falling gradually
Latency gets worse while target remains stable
CAPTCHA or redirect loops increase
The same target rejects the proxy repeatedly while others do not
At that point, the answer is usually not “retry harder.” It is to cool down, rotate away, or retire that IP.
Pool hygiene matters more than pool size
Having 50,000 terrible proxies is not an advantage. A smaller set of well tracked, high quality IPs can outperform a giant dirty pool very quickly.
This is one of the strongest operational arguments for using a managed provider with active health scoring. SocLeads handles a lot of this lifecycle management automatically, which saves a lot of troubleshooting time.
“robots.txt is not an access authorization mechanism. Those rules are publicly visible and rely on voluntary compliance.”
— Google Search Central
That quote is worth keeping in mind because it captures a point a lot of people miss. Robots directives matter operationally and reputationally, but they are not the same thing as technical access control. If you are building a responsible scraping program, understanding the difference helps you design behavior more carefully.
Practical scenarios and how proxy strategy changes
Scenario 1: All public listings are simple
Imagine that you are interested in scraping product names, product prices, URLs from an ecommerce category page on the public Internet. No log-in required, no dynamic shopping cart and low interaction levels.
-
Recommended setup: The data center or residential as per sensitivity of the site. On demand or as requested. This means that it doesn’t support high concurrency per domain. Normal browser like headers. This is typically sufficient for lightly protected sites.
Scenario 2: Geo sensitive search results
Perhaps you wish local pricing or city directories.
-
Recommended setup: Residential proxies that include city or region targeting. Break session pools into different pools depending on location. Where possible, consistent language and timezone alignment! The more your session metadata is similar to that of the selected geography, the purer the results will be.
Scenario 3: Multi page workflow and accounts
Now visualize a session that logs in, goes to multiple internal pages, applies filters, and goes back to previous views.
-
Recommended setup: ISP or sticky residential proxies are another option that you can use. Persistent cookie jar. Consistent user agent for the entire session. The rotation to complete after the workflow, not during. A change of identity midstream more often creates more problems than solutions.
Scenario 4: Social and heavily protected targets will be utilized
This is where the scraping becomes difficult and quality of the infrastructure is crucial.
-
Recommended setup: Residential/Mobile routes. Use the headless browser or managed rendering as needed. Conservative rate limiting. Aggressive observability and proxy scoring.
Build vs buy: why SocLeads is the stronger choice
Every scraping team, at some time, arrives at the same fork in the road. Is your proxy management stack an in-house thing or is it something you pay for that handles most of the complexity?
Option 1: Fully DIY
You acquire proxies, control rotations, monitor failures, create browser workflows, write parsers, process retries, keep dashboards up to date and adjust when targets change.
-
What you gain: Maximum control.
-
What you pay: Time, engineering concentration, and maintenance costs. More than often, more than expected.
Option 2: Use a proxy provider and your scraper
This will reduce the amount of network work, but the rest is up to you.
-
What you gain: The superfast launch compared to DIY.
-
What you still own: Session logic, browser orchestration, retry tuning, parsing reliability and block analysis.
Option 3: The fully managed scraping platform option
This is where SocLeads comes in. It’s not simply a proxy service with a dashboard. It is a more holistic scraping process and the moving elements are designed to function together.
Why SocLeads is better than using individual products
-
Unified anti block handling: Proxies, sessions, headers and rendering are optimized in one system. This is important because multi-faceted factors typically cause ban reduction, not just one setting. Typically originates from the interplay of all of them.
-
Adaptive routing: IP profiles must be different for various targets. SocLeads can use smarter defaults than a raw proxy list because it is capable of routing based on the characteristics of the target and its success rate.
-
Less infrastructure glue: Until a week ago this one sounded boring, but now you’ve spent a week debugging a problem that stems from the handoff between your browser cluster, your proxy pool and your parser. There are less moving parts, which translates to less hidden failure.
-
Improvements in speed to value: When you’re really only interested in getting usable data, but can’t care if you’re proving that you can build a proxy rotation subsystem from scratch, SocLeads gets you there quicker.
-
Improve fit with outbound and lead workflows: The number one business case typically isn’t “we took some pages.” It is “data turned into leads, campaigns.”
Doing it yourself can be very rewarding if you like the bottom of the hill. But, for those of you who have a business and are just looking for a good extraction, SocLeads is the better practical option most of the time.
Common mistakes that lead to bans fast
Some of the scraping failures seem to be complicated, but are actually very basic mistakes.
-
Selecting the wrong proxy type: One typical case is attempting to reach a high friction target using a discount datacenter IP. That level of traffic would never have been allowed to be sustained at the site.
-
Excessive rotation in stateful flows: It can appear very strange to change IPs when logging in or when a cart is moved from one page to another. Give the site continuity if it needs it.
-
Ignoring headers: A thin request profile, even if it has good IPs, can be blocked. You should have a session identifier that is internally consistent.
-
Too much concurrency: Many people think about number of proxies without taking into account concurrency control. A healthy pool can be consumed by 30 fast workers in no time at all.
-
No quality monitoring: You won’t be able to see which proxies, targets, or request patterns are failing, and you’ll be too late to react. It is not a luxury to have monitoring features. It’s a component of being on the web.
Checklist before you scale a scraper
-
Have you verified the target structure? There are different solutions for static HTML and browser rendered pages.
-
Do you have the correct proxy class selected? For easy targets: Datacenter, for tough ones: Residential / ISP.
-
Does rotation scheme reflect the working process? Sticky sessions for stateful flows (on request for stateless pages).
-
Are headers realistic? User agent, accept language and supporting headers should work together.
-
Do you have rate limits and backoff rules? Even the best proxies are not effective in noisy traffic.
-
Do you have the correct request metadata being logged? All of the following should be visible: Status, Latency, Session ID, Proxy ID, Target URL, Retries.
-
Tested small before attempting the bigger scale? There are 90 percent set up problems that can be identified by a small pilot run.
How this connects to broader scraping and lead generation work
Proxy strategy is not a separate technical hobby. It is the reliability layer under many practical growth workflows.
If you are collecting business data, local listings, contact pages, or social profile details, proxy stability determines whether your system produces a clean stream of inputs or collapses into retries and incomplete pages. It is one of those invisible layers that nobody talks about until it breaks everything.
That is also why proxy setup matters for more than just traditional page scraping. Once you move from pages to pipelines, questions like data quality and workflow efficiency come into play. A useful companion read is Email Scraper vs Email Finder: Which One Actually Fills Your Pipeline in 2026?. It helps frame the difference between gathering raw data and building an operational lead generation engine.
And if your scraping ultimately powers outreach, there is no point collecting records that later bounce or go nowhere. That is where validation and sequencing matter just as much as acquisition.
So, can you really “never” get IP banned?
Not literally. Any target can change policy, tighten rules, or deny access whenever it wants. But the real goal is not magical invisibility. It is reliability.
You want a scraper that moves from “blocked constantly” to “stable enough to operate without daily firefighting.” That is very achievable when you combine:
The right proxy type
Appropriate rotation and session logic
Believable request identity
Conservative rate control
Feedback driven monitoring
That combination is what actually reduces IP bans. Not one silver bullet. Not one clever trick. Just a system where each layer supports the others.
If you build it yourself, make sure you treat proxies as infrastructure, not as an afterthought. If you would rather skip the plumbing and focus on the data, SocLeads is the strongest path because it packages the hard parts into one more coherent operating model. Once you have spent enough time wrestling flaky proxy pools, that simplicity starts to look very valuable.
FAQ
What is the best proxy type for web scraping?
It depends on the target. Datacenter proxies are good for easier sites and cost efficient scaling. Residential proxies are better for anti bot heavy targets. ISP proxies are ideal when you need stable long lived sessions. Mobile proxies are for especially difficult environments where trust matters most.
How often should I rotate proxies when scraping?
For public, stateless pages, rotating every request or every few requests works well. For stateful workflows like logins or carts, use sticky sessions and rotate only after the full workflow completes or after a timed window.
Do proxies alone prevent 403 and 429 errors?
No. Proxies reduce risk, but they are only one part of a good setup. Headers, delays, cookies, browser behavior, concurrency, and session consistency all influence whether a site accepts or blocks your requests.
Are residential proxies always better than datacenter proxies?
Not always. They are usually better at avoiding bans, but they cost more and can be slower. For low friction websites, datacenter proxies may be perfectly adequate and much cheaper. The smart choice is matching proxy quality to target difficulty.
What is a sticky session in web scraping?
A sticky session means multiple requests from the same logical session are sent through the same IP for a period of time. This helps when the site expects continuity, such as login flows, shopping carts, or pagination with cookie based state.
Should I use my own proxy pool or a managed platform?
If you want maximum control and have engineering resources, a self managed pool can work. If you care more about reliable output and fast deployment, a managed platform is usually better. SocLeads is especially strong here because it combines proxy rotation, anti block logic, session handling, and extraction into one cleaner system.
Why do good proxies still get blocked sometimes?
Because sites do not rely on IP checks alone. They look at behavior, request pacing, cookies, browser fingerprints, location consistency, and historical patterns. Even clean IPs can fail if the surrounding traffic signals look suspicious.
Is proxy setup important for lead generation scraping too?
Absolutely. If your workflow depends on collecting data from websites, maps, directories, or social platforms, proxies are part of the foundation. Poor routing leads to partial data, retries, and missed records. Good routing keeps collection stable so the rest of your lead pipeline can function.